Recommended AWS CDK Project Structure for Monolithic Python Applications
July 17, 2023: Updated the guidance to align with Application Design Framework recommendations.
My Recommended AWS CDK project structure for Python applications blog post describes an application for a single bounded context - User Management Backend service. The application includes a dedicated repository with source code for the service and the toolchain. This is the option #4 in the figure below.
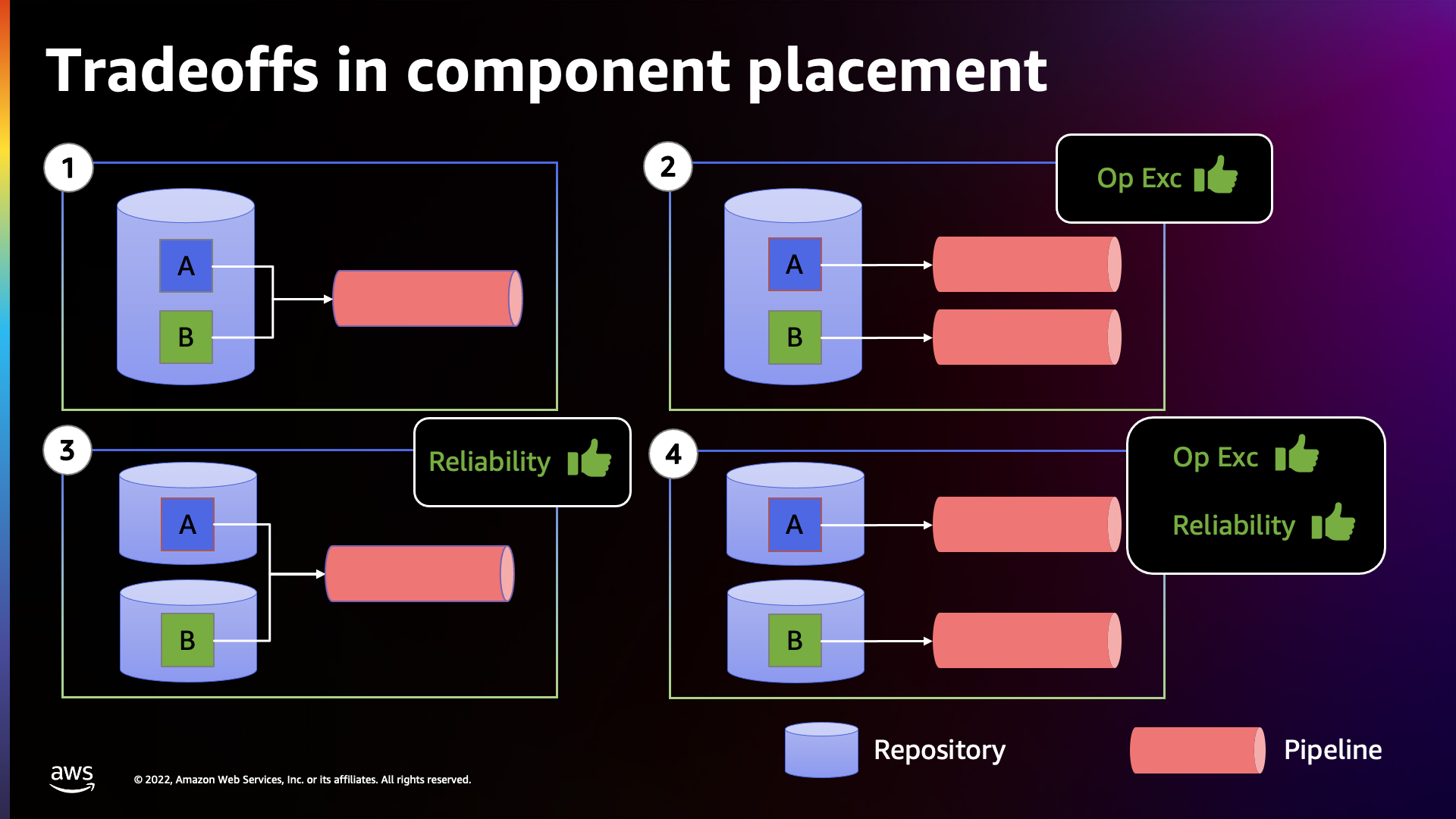
Source: https://d1.awsstatic.com/events/Summits/reinvent2022/DOP321_Organize-application-components-into-repositories-and-pipelines-with-AWS-CDK.pdf
Some builders initially prefer to start with an application that includes multiple bounded contexts - options #1 and #2 above. In this post, I describe the recommended AWS CDK project structure for these options, with #1 as the example.
Example application
Let’s assume the application boundary now includes the following bounded contexts: Admin Console and User Management (User Management Backend in the original post).
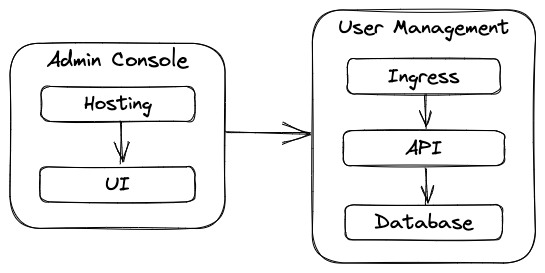
Application
Project structure
The application always includes at least service and toolchain components. Service includes functionality such as business logic and monitoring. Toolchain includes functionality such as deployment pipeline, pull request build, and tenant provisioning. Service and toolchain may include sub-components and eventually resources configuration and business logic. Below is the recommended project structure for the example application.
service/
admin_console/
ui/
index.html
hosting.py
user_management/
api/
app.py
ingress.py
database.py
service_stack.py
app.py
toolchain/
deployment_pipeline.py
toolchain_stack.py
Service includes Admin Console and User Management bounded contexts. Admin Console includes UI (e.g. React application) and hosting (e.g. CDN servers and storage). User Management includes API (e.g. Flask application), ingress (e.g. web application firewall, load balancer) and database (e.g. primary and standby instances).
Toolchain includes deployment pipeline (e.g. build, test, rollout).
Toolchain resources should exist before service resources, hence toolchain and service are going to be separate stacks: service_stack.py and toolchain_stack.py. Each stack deploys the associated resources and business logic.
I can deploy service resources as one stack or as two or more stacks. I’ll first cover one stack approach and then extend it to two or more stacks. I’ll use stack per bounded context as the example for the latter.
Service resources as one stack
app.py
This is the AWS CDK application entry point. The AWS CDK application composes together resources configuration and business logic.
import constants
from service.service_stack import ServiceStack
from toolchain.toolchain_stack import ToolchainStack
app = cdk.App()
ServiceStack(
app,
constants.APP_NAME + "-Service-Sandbox",
user_management_ingress_lambda_reserved_concurrency=1,
user_management_database_dynamodb_billing_mode=dynamodb.BillingMode.PAY_PER_REQUEST,
env=cdk.Environment(
account=os.environ["CDK_DEFAULT_ACCOUNT"],
region=os.environ["CDK_DEFAULT_REGION"],
),
)
ToolchainStack(
app,
constants.APP_NAME + "-Toolchain-Management",
env=cdk.Environment(account="111111111111", region="eu-west-1"),
)
app.synth()
I import and instantiate the service and toolchain stacks. Service resources deploy to sandbox environment based on caller credentials. Toolchain resources deploy to management environment based on specific configuration.
service/service_stack.py
ServiceStack class inherits the Stack class. Hosting, Ingress and Database classes inherit the Construct class. Stack outputs are defined in the ServiceStack class.
from service.admin_console.hosting import Hosting as AdminConsoleHosting
from service.user_management.ingress import Ingress as UserManagementIngress
from service.user_management.database import Database as UserManagementDatabase
class ServiceStack(cdk.Stack):
def __init__(
self,
scope: cdk.Construct,
id_: str,
*,
user_management_ingress_lambda_reserved_concurrency: int,
user_management_database_dynamodb_billing_mode: dynamodb.BillingMode,
**kwargs: Any,
):
super().__init__(scope, id_, **kwargs)
user_management_ingress = UserManagementIngress(
self,
"UserManagementIngress",
lambda_reserved_concurrency=user_management_ingress_lambda_reserved_concurrency,
)
user_management_database = UserManagementDatabase(
self,
"UserManagementDatabase",
dynamodb_billing_mode=user_management_database_dynamodb_billing_mode,
)
admin_console_hosting = AdminConsoleHosting(
self,
"AdminConsoleHosting",
user_management_api_endpoint=user_management_ingress.api_endpoint,
)
self.admin_console_ui_endpoint = cdk.CfnOutput(
self,
"AdminConsoleUIEndpoint",
value=admin_console_hosting.ui_endpoint,
)
I renamed the imports to preserve the bounded context information. I also used the bounded context as prefix for construct IDs. This allows to identify which bounded context the resources belong to within the stack also after deployment.
toolchain/toolchain_stack.py
ToolchainStack class inherits the Stack class.
import aws_cdk as cdk
import constants
from toolchain.deployment_pipeline import DeploymentPipeline
class ToolchainStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, id_: str, **kwargs: Any):
super().__init__(scope, id_, **kwargs)
DeploymentPipeline(self, "DeploymentPipeline")
toolchain/deployment_pipeline.py
DeploymentPipeline class inherits the Construct class.
from aws_cdk import pipelines
from constructs import Construct
import constants
from service.service_stack import ServiceStack
class DeploymentPipeline(Construct):
def __init__(self, scope: cdk.Construct, id_: str, **kwargs: Any):
super().__init__(scope, id_, **kwargs)
pipeline = pipelines.CodePipeline(self, "CodePipeline")
DeploymentPipeline._add_production_stage(pipeline)
@staticmethod
def _add_production_stage(self, pipeline: pipelines.CodePipeline) -> None:
production_stage = cdk.Stage(
pipeline,
"Production",
env=cdk.Environment(
account=PRODUCTION_ENV_ACCOUNT, region=PRODUCTION_ENV_REGION
),
)
service_stack = ServiceStack(
production_stage,
constants.APP_NAME + "-Service-Production",
stack_name=constants.APP_NAME + "-Service-Production",
user_management_ingress_lambda_reserved_concurrency=10,
user_management_database_dynamodb_billing_mode=dynamodb.BillingMode.PROVISIONED,
)
pipeline.add_stage(production_stage)
Deployment pipeline creates an instance of the ServiceStack and passes the production environment configuration parameters.
Service resources as stack per bounded context
Now I create a stack for each bounded context: admin_console_stack.py and user_management_stack.py. I keep the service_stack.py as the interface for the toolchain. service_stack.py will compose the bounded context stacks together.
service/
admin_console/
ui/
index.html
hosting.py
admin_console_stack.py
user_management/
api/
app.py
ingress.py
database.py
user_management_stack.py
service_stack.py
app.py
toolchain/
deployment_pipeline.py
toolchain_stack.py
There is no change in app.py and toolchain/deployment_pipeline.py, because the service interface doesn’t change.
service/service_stack.py
ServiceStack class is a regular object.
from service.admin_console.admin_console_stack import AdminConsoleStack
from service.user_management.user_management_stack import UserManagementStack
class ServiceStack:
def __init__(
self,
scope: cdk.Construct,
id_: str,
*,
user_management_ingress_lambda_reserved_concurrency: int,
user_management_database_dynamodb_billing_mode: dynamodb.BillingMode,
**kwargs: Any,
):
if "stack_name" in kwargs:
stack_name_prefix = kwargs["stack_name"]
del kwargs["stack_name"]
else:
stack_name_prefix = id_
user_management_stack = UserManagementStack(
scope,
stack_name_prefix + "-UserManagement",
stack_name=stack_name_prefix + "-UserManagement",
ingress_lambda_reserved_concurrency=user_management_ingress_lambda_reserved_concurrency,
database_dynamodb_billing_mode=user_management_database_dynamodb_billing_mode,
**kwargs,
)
admin_console_stack = AdminConsoleStack(
scope,
stack_name_prefix + "-AdminConsole",
stack_name=stack_name_prefix + "-AdminConsole",
user_management_api_endpoint=user_management_stack.api_endpoint,
**kwargs,
)
ServiceStack class is a proxy object. It passes scope as is to each bounded context stack. The callers always pass construct ID, and may optionally pass stack name. If the callers specify stack name, ServiceStack uses the stack name as prefix for each bounded context stack construct ID and stack name. Otherwise, ServiceStack uses the construct ID as the prefix. This approach allows to group bounded contexts under the same service namespace.
Since ServiceStack class is not a stack, it doesn’t (and can’t) define stack outputs. The bounded context stacks define their stack outputs. I can still define dependencies between the stacks if needed (explicitly or implicitly). For an example, I pass User Management API endpoint to Admin Console.
service/user_management/user_management_stack.py
UserManagementStack class inherits the Stack class.
from service.user_management.ingress import Ingress
from service.user_management.database import Database
class UserManagementStack(cdk.Stack):
def __init__(
self,
scope: cdk.Construct,
id_: str,
*,
ingress_lambda_reserved_concurrency: int,
database_dynamodb_billing_mode: dynamodb.BillingMode,
**kwargs: Any,
):
super().__init__(scope, id_, **kwargs)
ingress = Ingress(
self,
"Ingress",
lambda_reserved_concurrency=ingress_lambda_reserved_concurrency,
)
database = Database(
self,
"Database",
dynamodb_billing_mode=database_dynamodb_billing_mode,
)
cdk.CfnOutput(
self,
"APIEndpoint",
value=ingress.api_gateway_http_api.url,
)
self.api_endpoint = ingress.api_gateway_http_api.url
Here I don’t need to rename imports because the stack name will act as bounded context namespace.
service/admin_console/admin_console_stack.py
AdminConsoleStack class inherits the Stack class.
from service.admin_console.hosting import Hosting
class AdminConsoleStack(cdk.Stack):
def __init__(
self,
scope: cdk.Construct,
id_: str,
*,
user_management_api_endpoint: str,
**kwargs: Any,
):
super().__init__(scope, id_, **kwargs)
hosting = Hosting(
self,
"Hosting",
user_management_api_endpoint=user_management_api_endpoint,
)
cdk.CfnOutput(
self,
"UIEndpoint",
value=hosting.ui_endpoint,
)
Also here I don’t need to rename imports because the stack name will act as bounded context namespace.
Conclusion
In this post, I described the recommended AWS CDK project structure for monolithic Python applications. The blog post covered one stack and two or more stack deployment models. The application used a single deployment pipeline. If you want to create more than one deployment pipeline (e.g. deployment pipeline per bounded context), take a look at Integrate GitHub monorepo with AWS CodePipeline to run project-specific CI/CD pipelines blog post.
If you think I’ve missed something, feel free to ping me @alex_pulver. Happy coding!